Variables selection
The "Select data" tab allows the user to choose what parameters will be used to clustering the data.
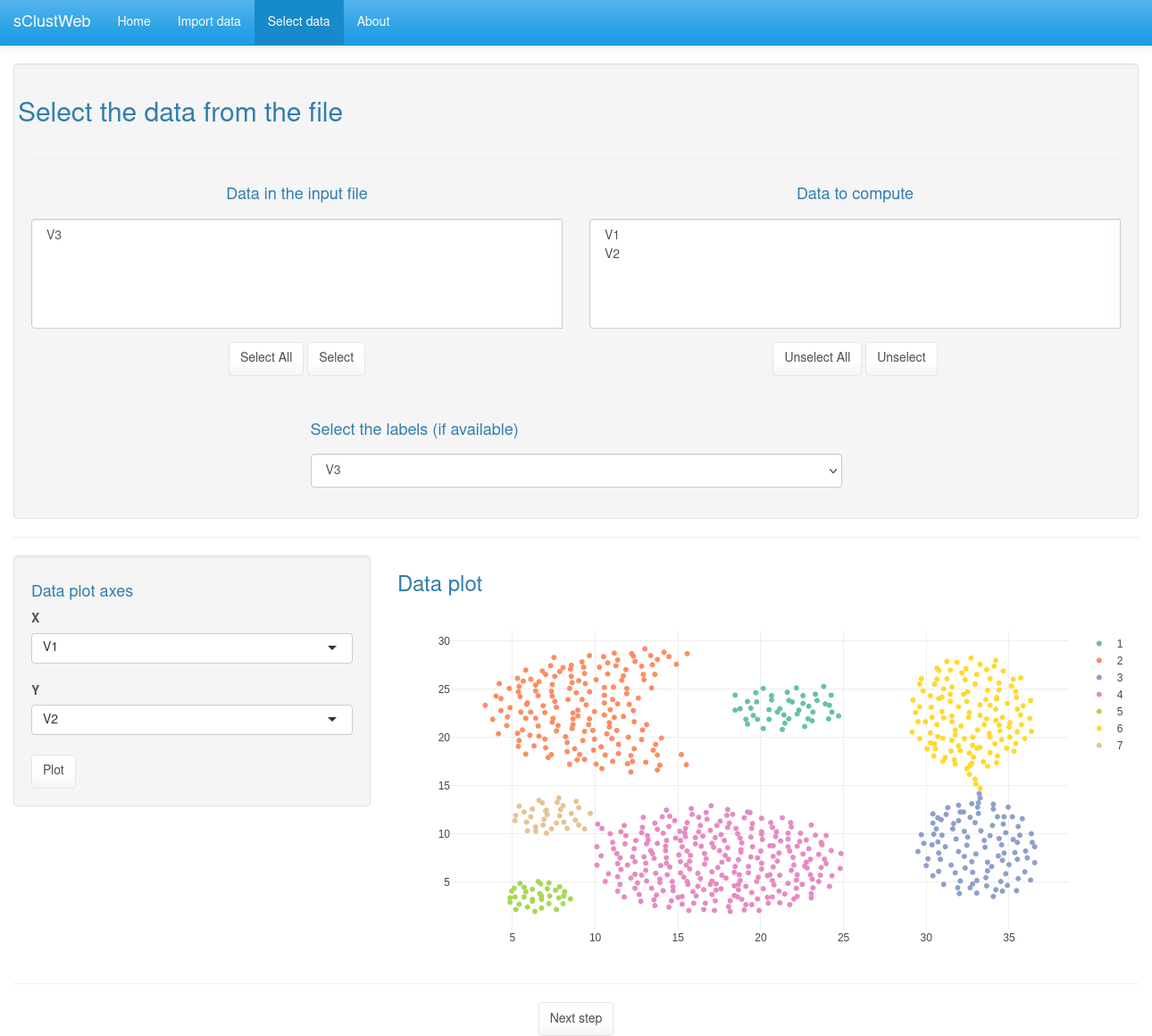
Figure 4: Select data tab
Select the data from the file frame
In the frame "Select the data from the file", the left list contains all the values present in the file and not yet selected and the right list contains all the values that have been selected for the clustering.
In this frame are several buttons that allow the user to interact with the lists : * The "Select All" button allows you to add all the variables with a single click ; * The "Select" button adds the selected variable(s) ; * The "Unselect All" button allows you to remove everything ; * The "Unselect" button allows to remove the selected variable(s).
The drop-down list "Select the labels (if available)" allows the user to select the column containing the real labels if it is available in the file. Otherwise, select "NA". The precision of this column in the interface, will allow in the results to have more information, especially with the scores and the correlation matrix
Plot frame
This part allows the user to quickly visualize the data present in the file. This can help him to select the parameters he will have to use for the clustering. Just select the two axes in the two drop-down lists and press the "Plot" button to show the plot.
Next step button
The "Next step" button validates the selected parameters and moves on to the next step which is the pre-process part.